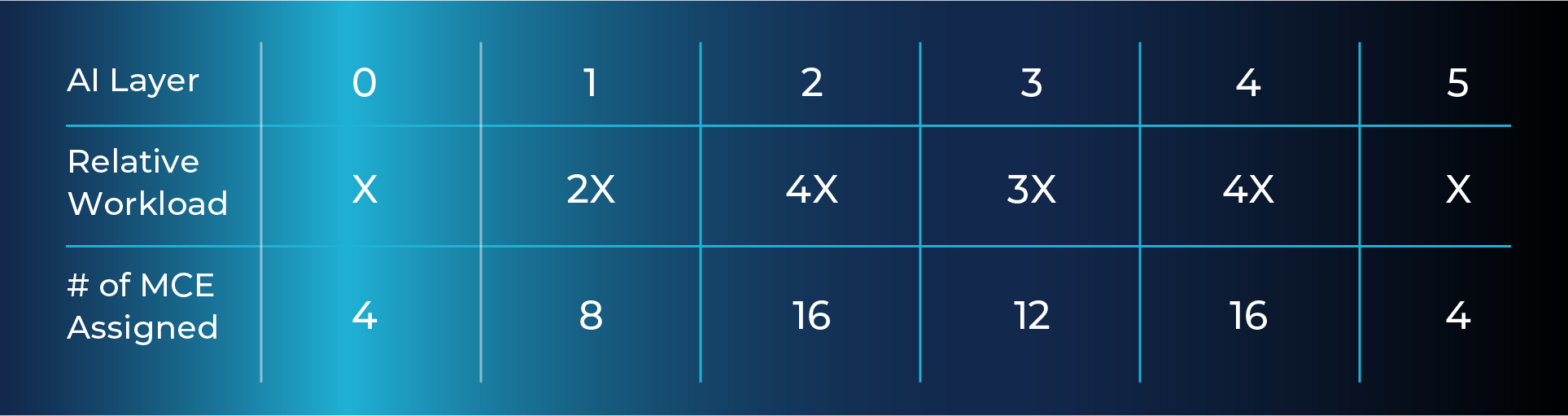Chip makers are always making design tradeoffs to balance performance, power, area, cost, quality, size, thermals, compatibility, efficiency, ease of use, and more.
But exceptional developers look beyond a chip spec sheet to the core architecture.
Core architecture is what sets MemryX solutions apart from competing AI alternatives. The hardware and software architectures were co-designed from the ground up, constrained not by spec sheet requirements, but by customer-friendly features such as maximizing HW/SW scalability, ease of implementation, compatibility to extend the AI processing of any Application Processor, and the flexibility to accommodate unknown future design requirements.
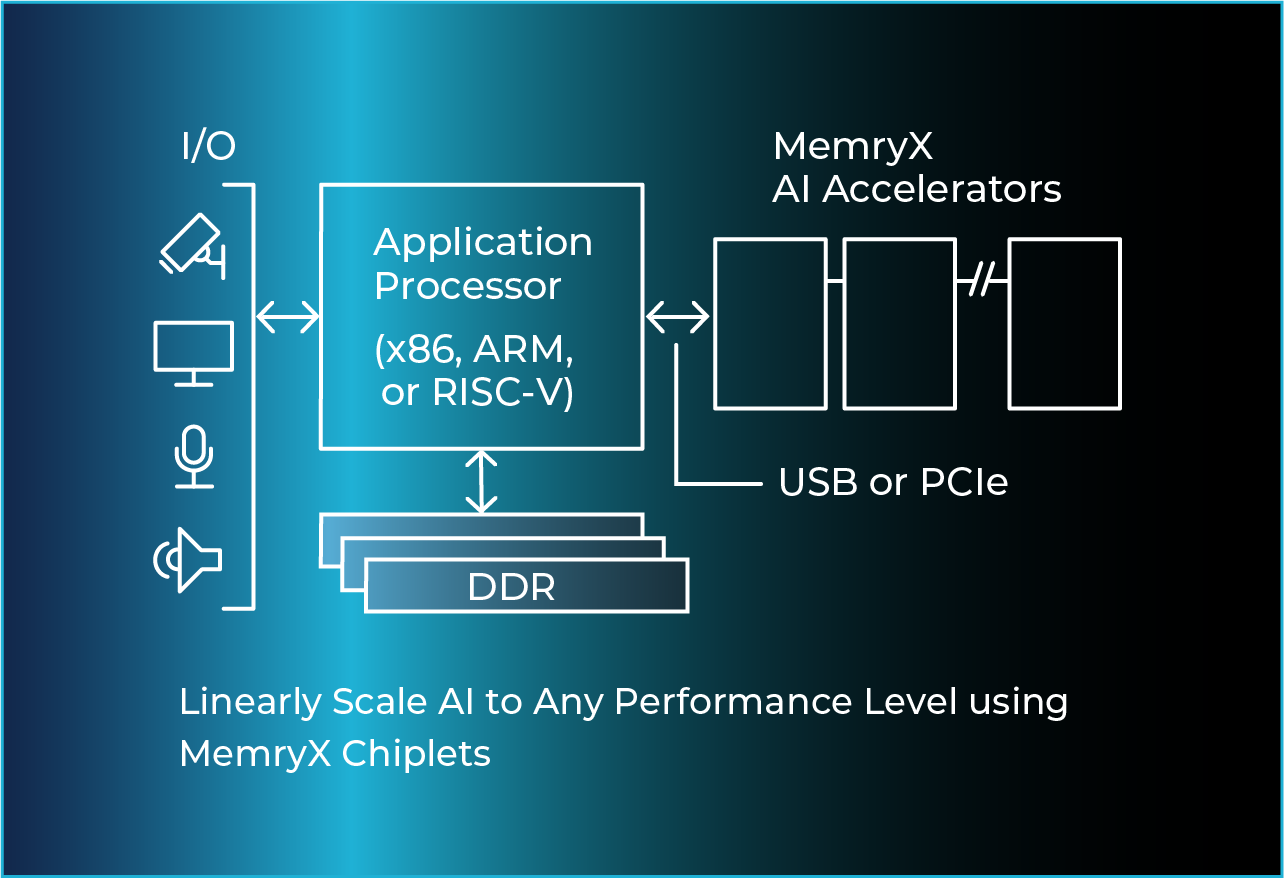
Add Advanced AI to any Host Processor
Adding memory capacity to any processor is easy. Our goal at MemryX is to make scaling AI processing nearly as simple.
MemryX chip(s) connect to standard I/O (USB or PCIe) for data input. They execute in a deterministic manner while not adding any processing burden to the host (on any OS), no matter how many chips are connected.
Purpose-Design for Advanced AI
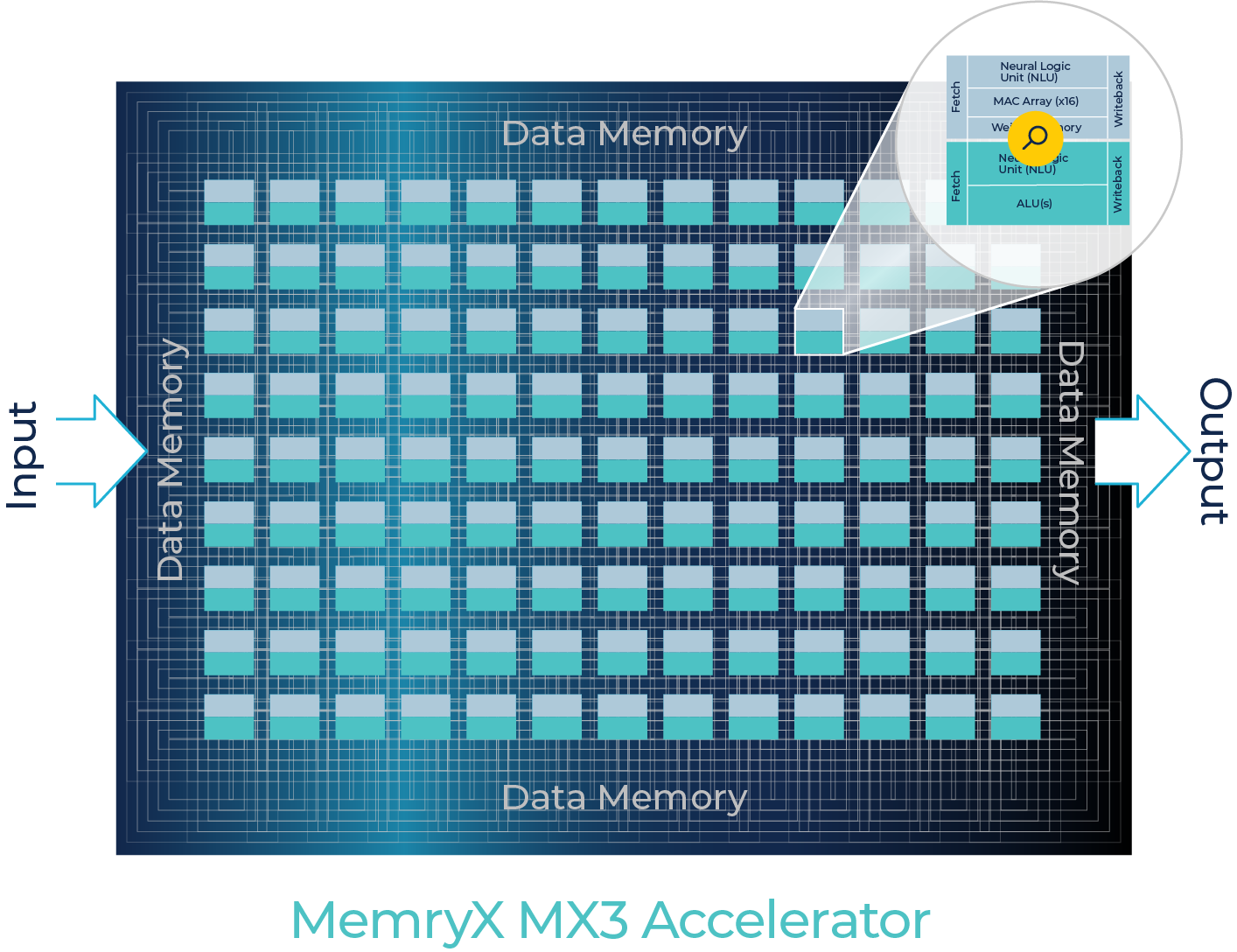
MemryX uses a proprietary, highly configurable native dataflow architecture.
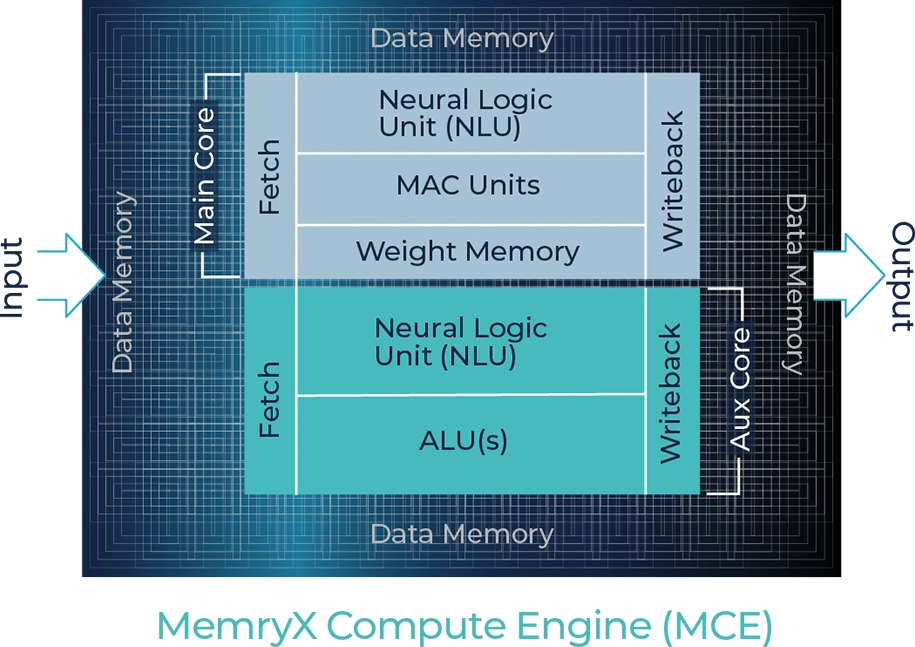
MemryX Compute Engine (MCE) are tightly coupled with innovative at-memory computing for superior AI processing at the Edge.
Unlike other solutions that rely on control planes or network-on-chips (NOCs) to manage complex data routing, MemryX’s native dataflow design achieves deterministic, high performance/utilization, low latency, and ease of mapping.
High Utilization
AI models cannot run efficiently using legacy instruction sets and traditional control-flow architectures found in CPUs, GPUs, and DSPs. These are all instruction-centric designs using traditional buses and network-on-chips (NoCs) to distribute workloads, and typically require significant software efforts to achieve even moderate chip utilization while running AI models. TOPS matter little.
MemryX uses a proprietary dataflow architecture with at-memory computing specifically designed for efficient compilation and mapping of trained AI models.
High chip utilization with 1-click saves development time, resources, unit costs, and offers the best upgradeability.
1-Click Optimization
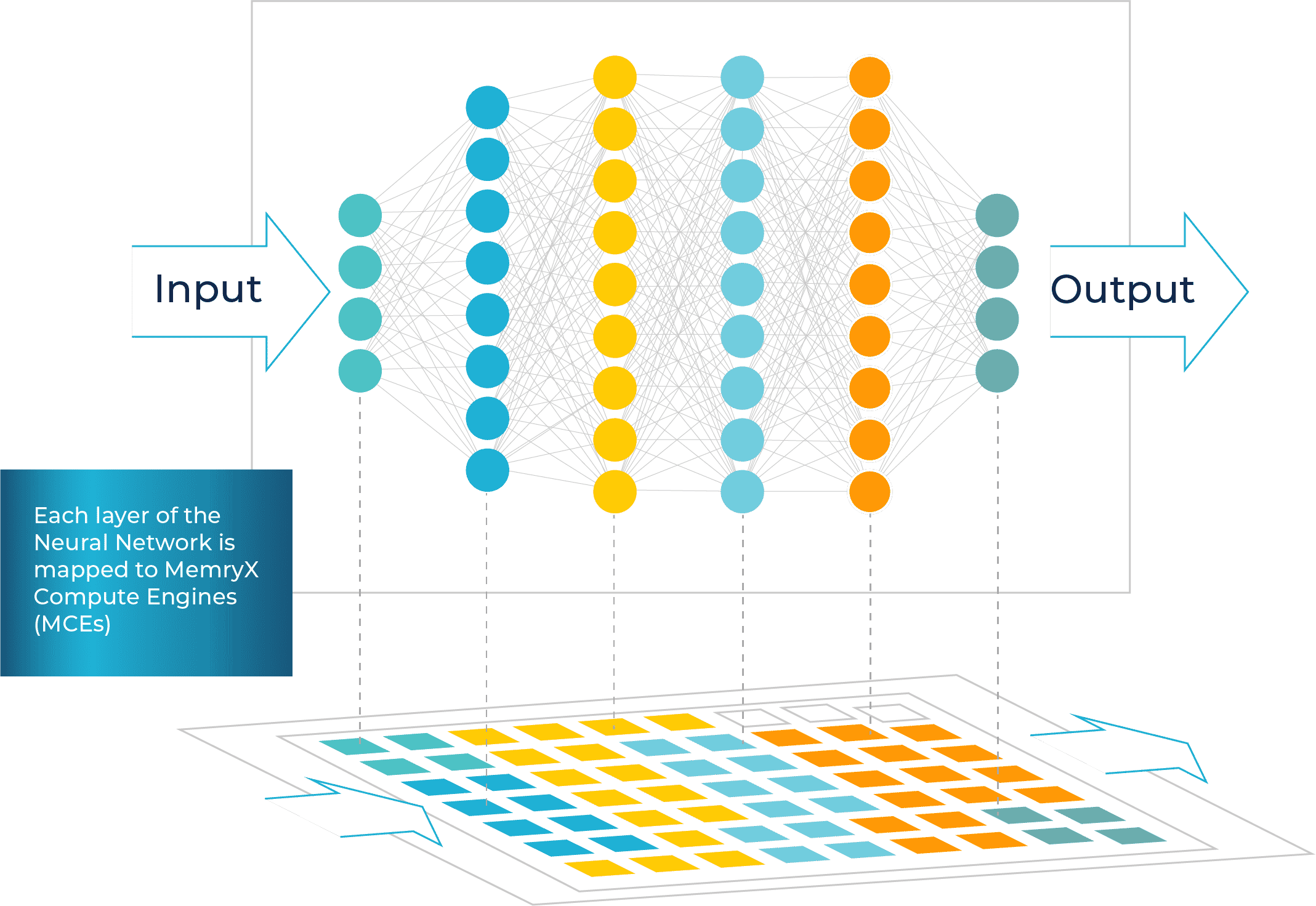
Example:
Mapping a Neural Network with 6 Layers
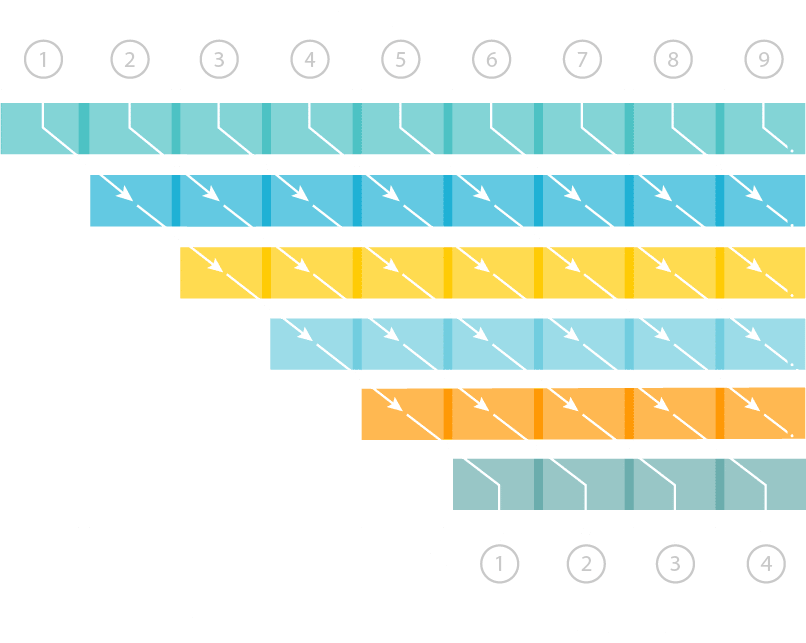
With 1-click compilation and mapping, each layer of the network is automatically assigned an appropriate number of computing resources. Ideally, each layer will take the same amount of time to process, creating highly efficient pipelined performance while simultaneously minimizing latency.
Pipelined Execution for High Performance / Low Latency
AI Optimized Dataflow Pipeline with Single Model
Deterministic performance for each frame with no system bottlenecks
All processing done with batch = 1 for real-time, streaming processing
Faster processing and lower latency by adding AI Processing Chips (e.g. double the “pipe” by adding double the AI processors)
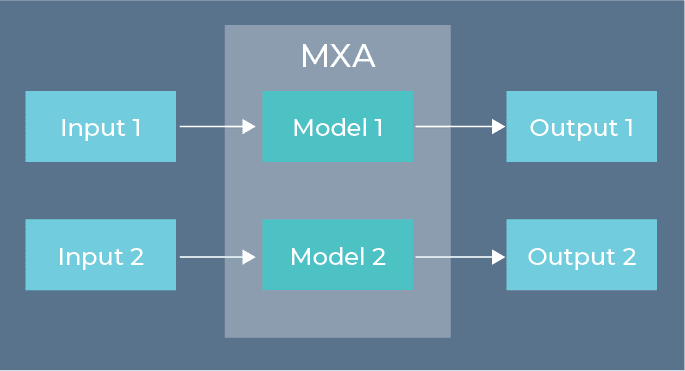
AI Optimized Dataflow Pipeline with Multiple Model (Each can run fully independent and Asynchronous)
Subscribe to our Newsletter
Do you want to receive the latest MemryX news in your inbox every month?