Three new products, one architecture. Cascade 100 now scales from 16-chip PCIe cards for high-density edge servers, to Raspberry Pi modules, to USB accelerators.
SDK v2.2 is our biggest update since 2.0, and includes numerous improvements and new features across the NeuralCompiler, driver, runtime, utils, and model explorer
Electromaker takes a hands-on look at the MemryX MX3, highlighting its plug-and-play setup, low power draw, and high AI performance for edge applications.
We found the MX3 M.2 module to be exceptionally easy to use … it is the first AI accelerator we’ve encountered for which both the hardware and the software “just works.”
2025 Edge AI & Vision Alliance Product of the Year award winner
MemryX’s MX3 M.2 AI Accelerator Module has been awarded the 2025 Edge AI and Vision Product of the Year Award in the Edge AI Computers and Boards category.
Quickly deploy one or more of your own AI models without being locked in a model zoo. Achieve high accuracy and performance without retraining or model tuning.
As the volume of video data increases, traditional computing solutions struggle to keep up with the demand for real-time processing and actionable insights. MemryX Edge AI solutions tackle this important transformation.
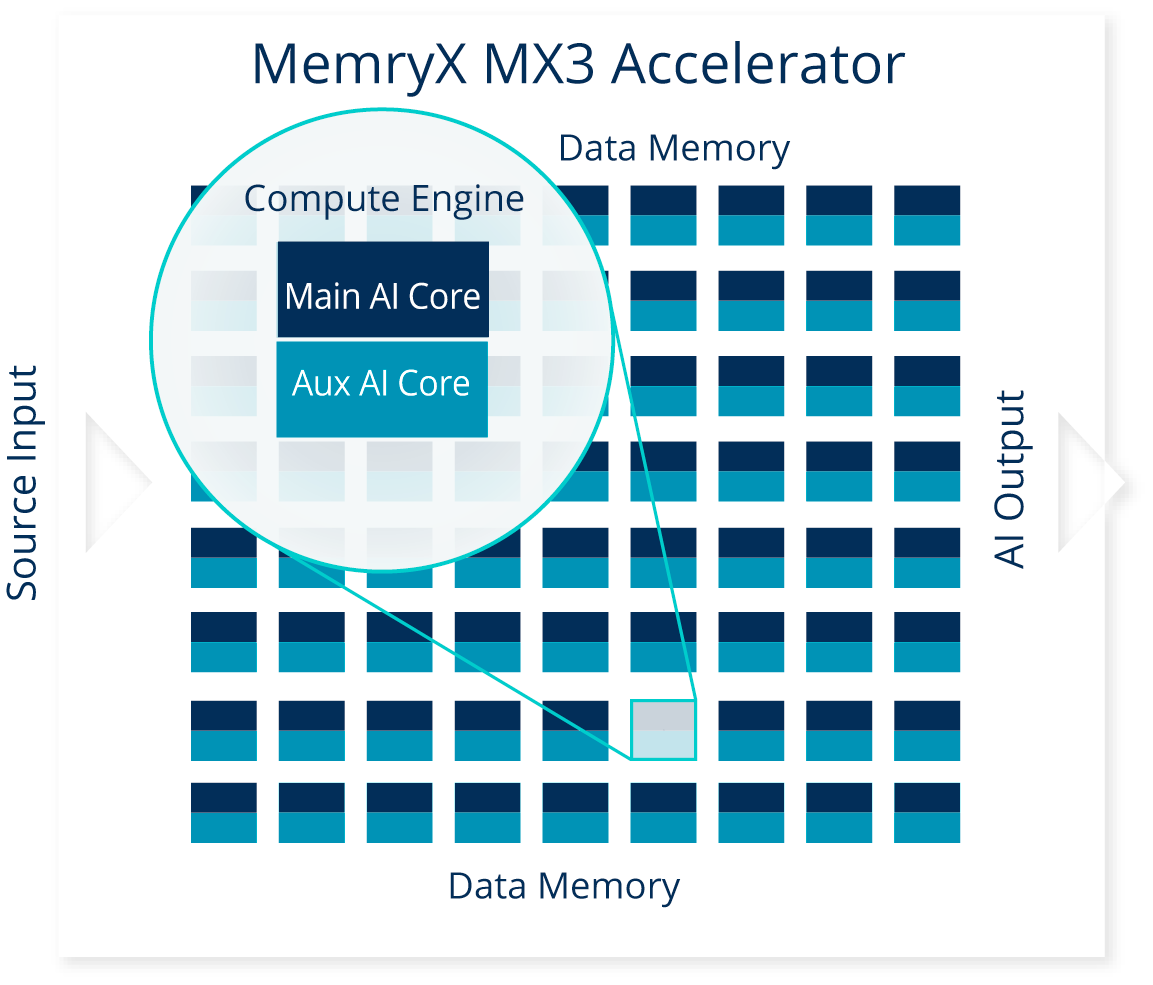
MemryX Edge AI combines an innovative dataflow architecture with at-memory computing to achieve breakthrough performance with low-power and more simple software integration.