Skip to content
Engineering Samples now available
Contact Us
Markets
Products
Technology
Developers
Developer Hub
GitHub
eXamples
Community
Buy Now
Amazon
WPG-A
Mouser
Company
About Us
Careers
Newsroom
Contact Us
Markets
Products
Technology
Developers
Developer Hub
GitHub
eXamples
Community
Buy Now
Amazon
WPG-A
Mouser
Company
About Us
Careers
Newsroom
Contact Us
Technology
Scale AI on any Host Processor
All MemryX chips work together as one logical unit, with a single connection to the host using a standard interface (PCIe or USB).
Fully offload AI models while only using the host for pre and post processing.
Supports x86, ARM, and RISC-V processors and Windows and Linux operating systems.
Watch Full Animation
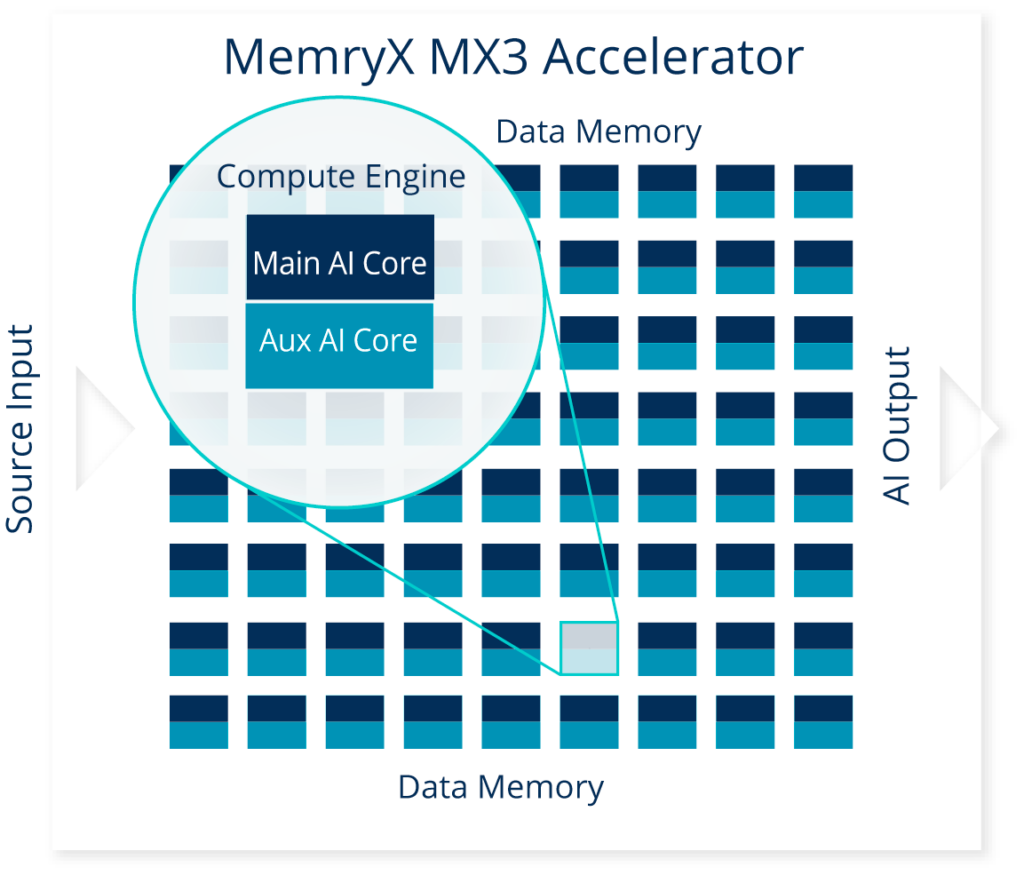
At-Memory AI Processing
High bandwidth at-memory computing eliminates memory bottlenecks.
Innovative, highly configurable native dataflow architecture adapts to your AI models.
Memory is the only interconnect used between compute engines, rather than managing data movement with a control plane or a network-on-chip (NoC).
Performance and Accuracy without a Model Zoo
>2X higher utilization than any competitor enables the MX3 to outperform others with higher TOPS/TFLOPS.
BF16 activations (in an efficient Block Floating Point format) ensure high accuracy without a user needing pilot images or retraining.
Compiler and Mapper are more efficient than any human in optimizing compute resources for any model.
The result: Users with high or limited expertise can easily use our online software tools to efficiently run their own model.
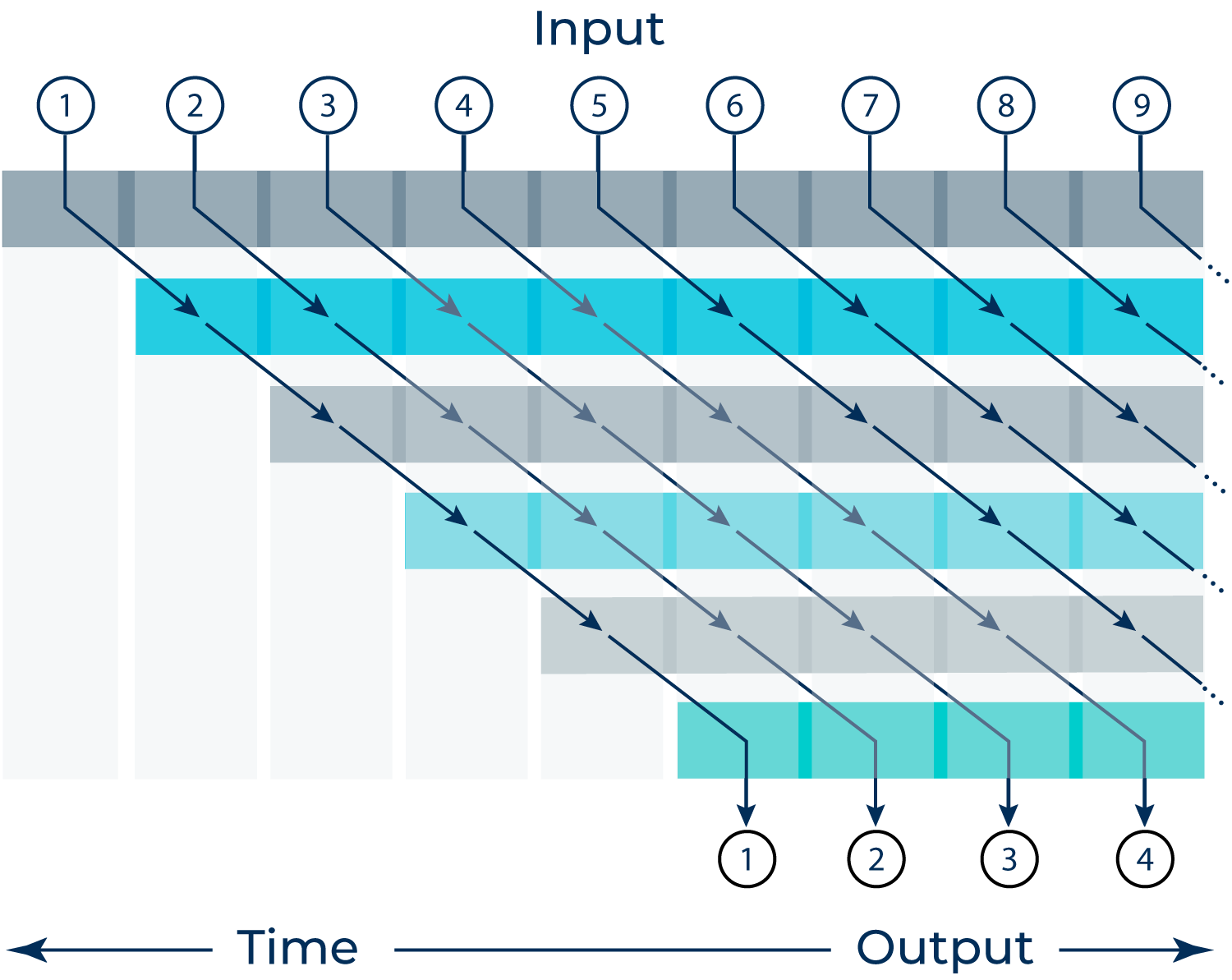
Pipelined Execution
Dataflow enables pipelined operation which is ideal for streaming inputs
(such as cameras).
Unlike CPUs, GPUs, or AI Accelerators with control flow, our architecture minimizes data movement for maximum efficiency.
Data is seamlessly streamed within a chip and across any number of chips.
Every input is processed identically, providing deterministic performance.
All data is processed with batch = 1.